
What is the Apache-Pig?
We can define Pig as tool or platform. Analyzing large set of data uses this tool. It represents them as the data flow. We generally use this Pig with the Hadoop. We could perform different kind of data manipulations and operation in the Hadoop. This is possible using the Apache Pig.
Pig is one of the high-level languages. Writing the programs for data analysis is simple with Pig. Generally, we call it as the Pig Latin. It provides all variety of operators. Using this, the programmers can able to develop functions by their own. Especially for writing, reading as well as processing the data.
For analyzing this data using the Apache Pig, programmer must need to code the scripts. This is possible with the help of Pig Latin. All the scripts will internally convert to the Map as well as Reduce task. The Pig engine is one of the Apache Pig components. This will accept the scripts as the input. Also, it converts these scripts into the MapReduce jobs.
Where to use Pig Latin?
The Pig is the high level open-source data flow systems. This will provide the simple language known as Pig Latin. This is for queries as well as the data manipulation. These will be then compiled into MapReduce jobs and run on the Hadoop.
The Pig is very important for companies like Microsoft, Google as well as Yahoo. These will collect a huge amount of data set. It will be in the click stream form, search logs as well as web crawls. This pig is also helpful for some forms of the ad-hoc process. Also, for the all the information analysis.
Why Do we Need the Pig?
Following are some of the reasons for the necessary of the Pig. They are,
- It is very easy for learning. Especially if we have knowledge with the SQL.
- Pig’s approach for multi-query will reduce the greater number of scanning the data. It means 1/20th lines of the code as well as 1/16th of development times. This is where we compared to write the raw MapReduce.
- The performance of the Pig is in pair with the raw MapReduce.
- The Pig will provide the data operation like joins, ordering, filters and more. Also, the nested data type like maps, tuples as well as bags.
- The Latin is very easy for writing as well as reading.
Why was the Pig Created?
Yahoo originally develop the Pig in 2006. This is especially for the researchers to create the ad-hoc as well as execute the MapReduce jobs. This will be on the large data set. The main reason for creating this is to reduce time taken for the development. It is possible with the help of the approach of multi querying. Also, they created this for experts from the non-Java backgrounds. This is mainly for making their jobs easier.
Where we should use the Pig?
We can use the Pig under the following scenarios. They are,
- When the data load is very time sensitive
- When they process various sources of data.
- When the analytical insight will require through the sampling.
Where we should Use Pig?
- In the place where data will completely unstructured. This is like audio, video as well as readable texts.
- In the place where the time will constraint exist, as the Pig is very slower than the MapReduce job.
- In the place where large power will require for optimizing the code.
Features of the Pig:
Pig has some of following feature. They are,
- Rich sets of the operators:
It provides a greater number of operators to performs the operation. This is like sort, filer, join and more - Easy programming:
The Latin is like SQL. Also, it is very easy for writing the scripts if we sound good in SQL. - Optimization of the opportunities:
Apache Pig tasks can automatically optimize their executions. Therefore, the programmers want to focus on the semantics of this languages. - Extensibility:
The user can concentrate more on developing their functions. This is possible with the help of existing operators. This is specially to write, read as well as process the data. - UDF:
The Pig provides more facility for creating a User-defined Function. This is possible with the help of other languages like Java. Also, it will invoke / embed in the Pig Scripts. - Handles all data:
All type of data can analyze by the Pig. It includes both the structured and unstructured. It will store the result in the HDFS.
Comparison between Apache Pig & MapReduce:
Following are some of the major difference between the Apache Pig as well as MapReduce.
| S:NO | Pig | Map-Reduce |
|---|---|---|
| 1 | It is the data flow programming language. | It is the processing paradigm of the data. |
| 2 | It is the high-level programming language. | MapReduce is a low level as well as rigid. |
| 3 | Perform the Join operations in Pig is very simple. | Perform the join operations is very difficult in the Map-Reduce. It will be between the datasets. |
| 4 | Any novice programmers with the basic knowledge about SQL can able to work more conveniently with the Pig. | Exposure to the Java language is must for working with the Map-Reduce. |
| 5 | Pig uses the approach of multi querying. So, it will reduce the code length at the great extent. | It will require 20 times more than the number of the lines for performing same task. |
| 6 | We don’t need for the compilation. On the time of execution, every pig operator will convert internally to the Map-Reduce job. | Map-Reduce job have the process of the long compilation. |
Comparison between the Apache Pig & SQL:
Major differences: Apache Pig and SQL are listed.
| S:NO | Apache PIG | SQL |
|---|---|---|
| 1 | Latin is the procedural language. | SQL is the declarative language. |
| 2 | Pig provides very limited opening. This is0 for the Query optimizations. | More feasibility for the query optimizations in the SQL. |
| 3 | In Pig, the schema is simply optional. It is possible to store the data without a schema design. | Schema is only mandatory in the SQL. |
| 4 | The data models in the Pig will be in the nested relations. | The data models used in the SQL is very flat relational. |
Added to the above listed differences, Pig Latin has the following. They are,
- Allow the splits in pipelines.
- Allow the developers for storing anywhere these data in pipelines.
- Declare the plans of executions.
- Provide the operator to perform the ETL functions.
- To process the huge data source like the web logs.
- To perform the data process for the search platform.
- To process more time sensitive for the data load.
- Atom – It is a simple atomic data value. It will store as a string but can use as either a string or a number.
- Tuple – An ordered set of fields.
- Bag – A collection of tuples.
- Map – set of key value pairs.
Comparison between the Apache Pig & Hive:
Creating MapReduce jobs uses both the Pig as well as Hive. Also, in some other cases, the Hive operates with the HDFS. This will be in the similar way as the Pig does. The table which follows have the few different points. These will set the Apache Pig from the Hive.
| S:NO | Pig | Apache Hive |
|---|---|---|
| 1 | Pig uses the language known as Pig Latin. Yahoo originally created this. | Hive uses the language known as HiveQL. Facebook originally created this. |
| 2 | Latin is the data flow programming language. | HiveQL is the query processing programming language. |
| 3 | Latin is the procedural language. Also, it fit in the pipeline paradigms. | HiveQL is the declarative languages. |
| 4 | Pig can also handle the structured, unstructured as well as semi-structured. | Hive is widely for the structured type. |
Application of the Pig:
Data Scientists use Apache Pig. Apache Pig performs the task which involves the ad-hoc processing as well as quick prototyping. Following are some important usage of Pig,
History of the Apache Pig:
In the year of 2006, Yahoo developed the Apache Pig as the research project. Especially this is to create as well as execute the MapReduce job. This will be on every data set. In the year of 2007, Pig was an open sourced through the incubator of Apache. In the year of 2008, they release the first section of the Apache Pig. In the year of 2010, Pig graduated as the top-level projects.
Architectural view of the Pig:
Pig Latin is the language which is used to analyze data in the Hadoop. It is a high-level programming language with data processing. It will provide the rich sets of data type. Also, it allows operator to perform more operations on these data.
For performing the task Programmers use this Pig. The programmers may want to write the Pig script. This is possible by using the Latin language. Also execute them by using any execution mechanisms. After this execution, the script will go through the steps of transformations. This will apply by the framework of the Pig, for producing the output.
Pig convert the script into serious of Map-Reduce job. Also, it makes the job of the programmer easier. Following shows the architecture of the Apache Pig.
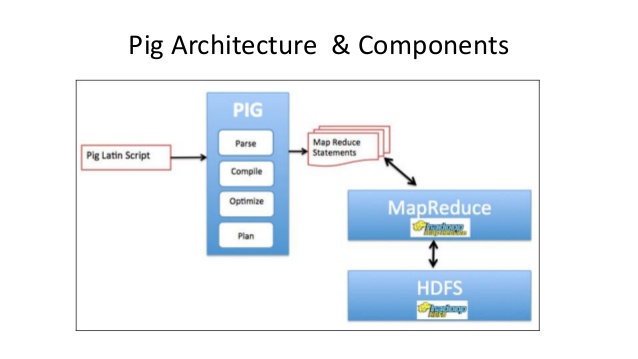
Apache Pig Components:
There are various components in the Apache Pig framework. The diagram highlights the same. Let us look at the major components
Parsers:
Initially the Scripts of the Pig will handle by the Parsers. It will check syntax of the scripts, also it checks the type, and more miscellaneous check. The parser output will be the DAG. It will represent the Latin statement & the logical operators.
In DAG, the logical operator of script will represent as nodes. Also, the data flow will represent as the edge.
Optimizers:
The logic plan is to pass the logical optimizers. It will carry out logical optimization. Projection and push down are major operations.
Compilers:
The compilers will compile the logical plan of optimizer. This will be in the series of the MapReduce job.
Execution engines:
At the end, the MapReduce job is submitted to the Hadoop. This will be in the sorted form. These Map-Reduce job will execute on the Hadoop. This will produce the desired result.
Small Intro about Pig Latin:

Pig Latin program will make up of the series of operations or transformations. That are applied to the input data to produce output. The job of Pig is to convert the transformations. This will be into the series of the MapReduce jobs.
Basic Types of Data Models in Pig:
Pig comprises 4 basic types of data models. They are as follows.
Conclusions:
I think that now you understand the basic concept of the Pig. All the above concept gives you more interest in learning the Pig. Learning this Pig will boost your carrier. I hope this article values your time.